# Multimodal Model Workflow
Roboflow Workflows मल्टिमोडल मॉडल्स का Workflows में उपयोग करने का समर्थन करता है।
चार सामान्य-उद्देश्य के मल्टिमोडल मॉडल हैं जिन्हें आप व्यापक कार्यों के लिए उपयोग कर सकते हैं। ये हैं:
* GPT-4o
* Claude
* Gemini
* Florence-2
इन मॉडलों का उपयोग निम्नलिखित कार्यों के लिए किया जा सकता है:
* एकल और बहु-लेबल छवि वर्गीकरण
* शून्य-शॉट ऑब्जेक्ट डिटेक्शन
* इमेज कैप्शनिंग जेनरेशन
* और भी बहुत कुछ
Workflows में मल्टिमोडल मॉडल का उपयोग करने के लिए, आपको:
1. मॉडल जोड़ना होगा।
2. एक टास्क प्रकार चुनना होगा।
3. एक बिल्ट-इन कनेक्टर का उपयोग करें जो मॉडल के परिणामों को अन्य Workflows ब्लॉक द्वारा समझे जाने वाले फॉर्मेट में परिवर्तित करता है।
आइए इन प्रत्येक चरणों को एक-एक करके देखें।
### मल्टिमोडल मॉडल जोड़ें
Workflows में Claude, Gemini, या GPT-4o का उपयोग करने के लिए, आपको उस मॉडल से संबंधित ब्लॉक जोड़ना होगा जिसे आप उपयोग करना चाहते हैं।
इस गाइड के लिए, चलिए Claude उपयोग करने वाले एक उदाहरण के माध्यम से चलते हैं।
ब्लॉक जोड़ने के लिए “Add Block” क्लिक करें। फिर Claude के लिए खोज करें:
\\
एक कॉन्फ़िगरेशन पैनल दिखाई देगा जिसमें आप Claude ब्लॉक को कॉन्फ़िगर कर सकते हैं।
{% hint style="info" %}
यदि आप कोई भी मल्टिमोडल मॉडल उपयोग करते हैं जो बाहरी API को कॉल करता है (जैसे GPT-4o), तो आपको अपना मॉडल API कुंजी सेट करनी होगी।
{% endhint %}
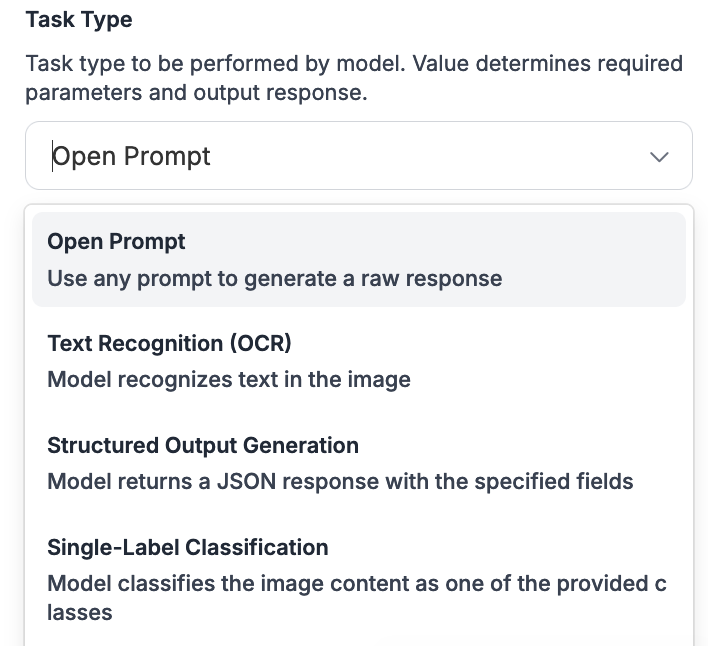
आप Claude (और Gemini और GPT-4o) का उपयोग कई कार्यों के लिए कर सकते हैं, जिनमें शामिल हैं:
* Open prompt: आपका प्रॉम्प्ट सीधे मल्टिमोडल मॉडल को पास किया जाता है।
* Text recognition (OCR): छवि में अक्षरों को पढ़ता है।
* Structured output generation: निर्दिष्ट फॉर्मेट में डेटा लौटाता है।
* Single-label और multi-label classification: छवि की सामग्री का प्रतिनिधित्व करने वाले एक या अधिक लेबल लौटाता है।
* Visual question answering: छवि की सामग्री के बारे में किसी विशिष्ट प्रश्न का उत्तर देता है।
* Captioning: एक इमेज कैप्शन लौटाता है।
* Unprompted object detection: छवि में वस्तुओं के स्थान के अनुरूप बॉन्डिंग बॉक्स लौटाता है।
आप Task Type ड्रॉपडाउन का उपयोग करके इन कार्यों में से चुन सकते हैं:
एक बार जब आप एक टास्क प्रकार चुन लेते हैं, तो ब्लॉक का आउटपुट स्वचालित रूप से आपके Workflow आउटपुट में जोड़ दिया जाएगा।
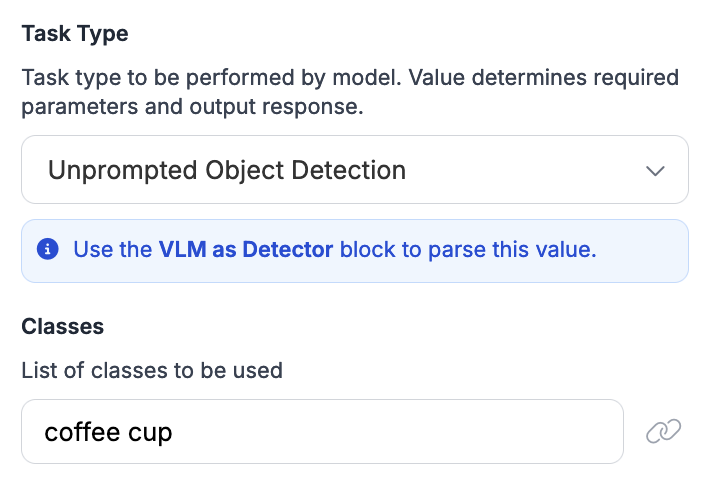
यहाँ ऑब्जेक्ट डिटेक्शन के लिए एक उदाहरण कॉन्फ़िगरेशन है:
### एक कनेक्टर जोड़ें
यदि आप मल्टिमोडल मॉडल के आउटपुट को अन्य ब्लॉकों में उपयोग करना चाहते हैं, तो आपको एक कनेक्टर जोड़ना होगा।
आप कनेक्टर्स का उपयोग इनको प्रोसेस करने के लिए कर सकते हैं:
* वर्गीकरण, और;
* बॉन्डिंग बॉक्स।
उदाहरण के लिए, आप Claude 3 द्वारा समर्थित शून्य-शॉट ऑब्जेक्ट डिटेक्शन से बॉक्स मान प्राप्त करने के लिए एक कनेक्टर जोड़ सकते हैं।
यह कनेक्टर उन बॉक्सों को इस तरह प्रोसेस करेगा कि आप उन्हें Bounding Box Visualization और Label Visualization जैसे Visualization ब्लॉक्स में उपयोग कर सकें।
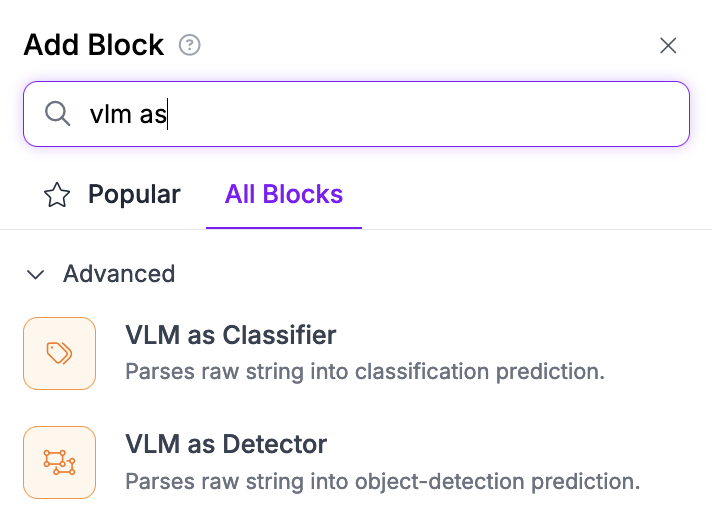
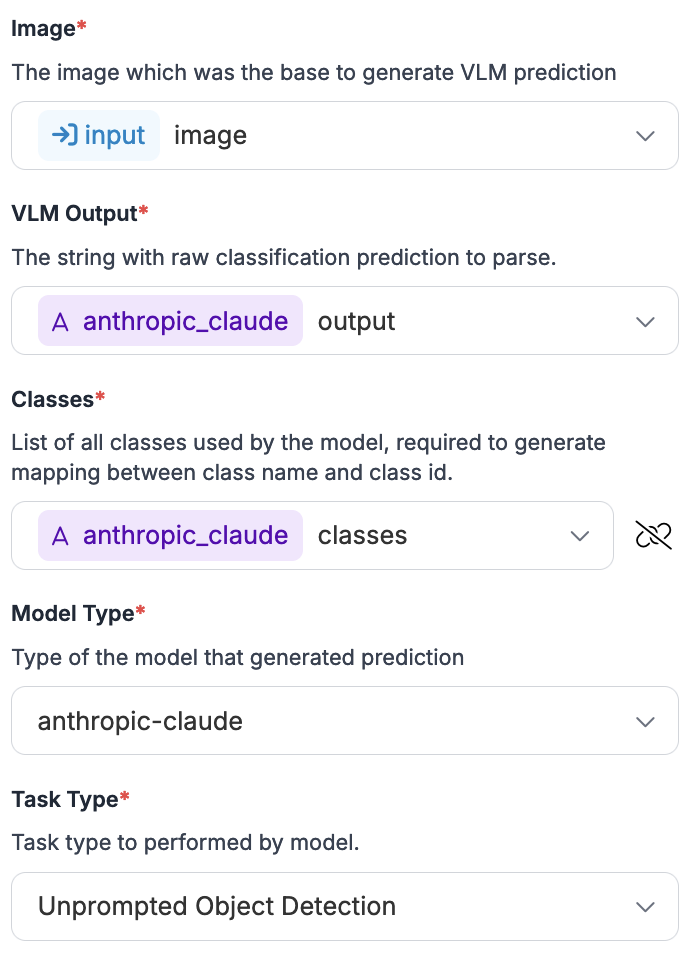
जब आप एक VLM कनेक्टर का चयन करते हैं, तो इसे उपयोग करने के लिए कॉन्फ़िगर करें:
1. आपकी इनपुट इमेज
2. आपके मल्टिमोडल ब्लॉक से आउटपुट
3. आपके मल्टिमोडल मॉडल की क्लासेज़
4. आप जो मल्टिमोडल मॉडल उपयोग कर रहे हैं उसका नाम (इस उदाहरण में, `anthropic-claude`)
5. जब आपने अपना मल्टिमोडल मॉडल सेटअप किया था तो आपने जो टास्क प्रकार चुना था
यहाँ एक उदाहरण कॉन्फ़िगरेशन है *VLM as Detector* ब्लॉक:
आप फिर कनेक्टर आउटपुट को अन्य ब्लॉकों के साथ उपयोग कर सकते हैं।
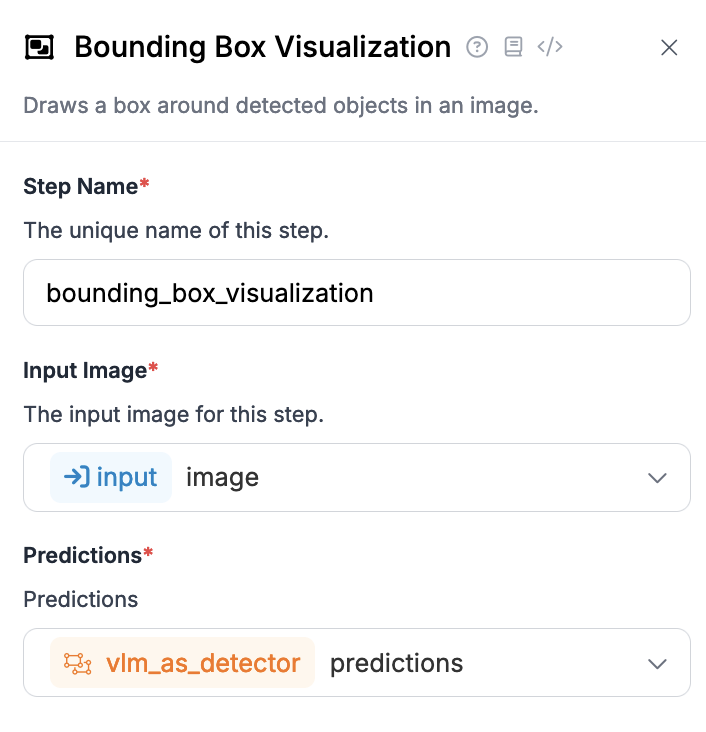
उदाहरण के लिए, आप कनेक्टर आउटपुट का उपयोग Bounding Box Visualization ब्लॉक के साथ बॉन्डिंग बॉक्स प्रदर्शित करने के लिए कर सकते हैं। Bounding Box Visualization ब्लॉक को आपकी इनपुट इमेज और VLM as Detector ब्लॉक से परिणामों के साथ कॉन्फ़िगर किया जाना चाहिए:
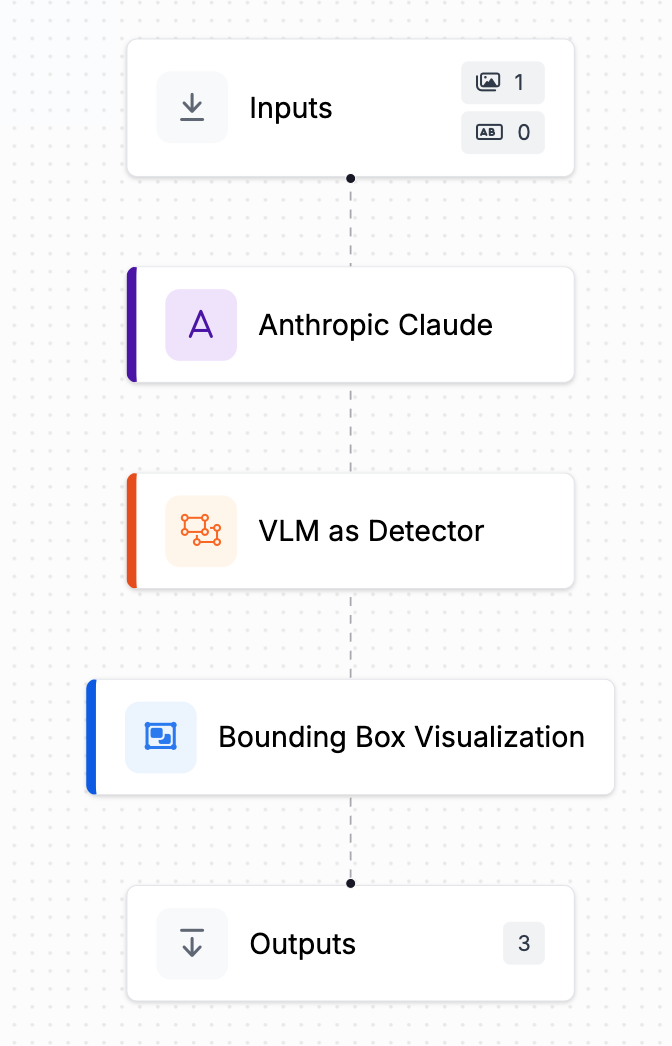
यहाँ एक[उदाहरण workflow](https://app.roboflow.com/workflows/embed/eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ3b3JrZmxvd0lkIjoiUE9YWklzY3VHNzNyMloxQ2JvM3AiLCJ3b3Jrc3BhY2VJZCI6ImtyT1RBYm5jRmhvUU1DZExPbGU0IiwidXNlcklkIjoiSW1GTElaU2tHYk55OXpiNFV1cWxNelBScHBRMiIsImlhdCI6MTczODE5ODA5Nn0.lZjVkJ5GNalFv60YDeHRkONZl5ml_Py2XZgpWcijVtU) है जो ऑब्जेक्ट डिटेक्शन के लिए एक मल्टिमोडल मॉडल का उपयोग करता है: