# マルチモーダルモデル Workflow
Roboflow Workflows は、Workflows でマルチモーダルモデルを使用することをサポートしています。
さまざまなタスクに使用できる、汎用のマルチモーダルモデルが 4 つあります。これらは以下のとおりです:
* GPT-4o
* Claude
* Gemini
* Florence-2
これらのモデルは、次のようなタスクに使用できます:
* 単一ラベルおよび複数ラベルの画像分類
* ゼロショット物体検出
* 画像キャプション生成
* その他
Workflows でマルチモーダルモデルを使用するには、次のことが必要です:
1. モデルを追加する。
2. タスクタイプを選択する。
3. モデルの結果を、他の Workflows ブロックが理解できる形式に変換する、組み込みコネクタを使用する。
各ステップを順に見ていきましょう。
### マルチモーダルモデルを追加する
Workflows で Claude、Gemini、または GPT-4o を使用するには、使用したいモデルに対応するブロックを追加する必要があります。
このガイドでは、Claude を使う例を見ていきましょう。
「Add Block」をクリックしてブロックを追加します。次に、Claude を検索します:
\\
Claude ブロックを設定できる設定パネルが表示されます。
{% hint style="info" %}
外部 API を呼び出すマルチモーダルモデル(つまり GPT-4o)を使用する場合は、モデルの API キーを設定する必要があります。
{% endhint %}
Claude(および Gemini と GPT-4o)は、次のような複数のタスクに使用できます:
* Open prompt: プロンプトをマルチモーダルモデルに直接渡します。
* Text recognition (OCR): 画像内の文字を読み取ります。
* Structured output generation: 指定された形式でデータを返します。
* Single-label and multi-label classification: 画像の内容を表す 1 つ以上のラベルを返します。
* Visual question answering: 画像の内容についての特定の質問に答えます。
* Captioning: 画像のキャプションを返します。
* Unprompted object detection: 画像内の物体の位置に対応するバウンディングボックスを返します。
Task Type ドロップダウンを使用して、これらのタスクから選択できます:
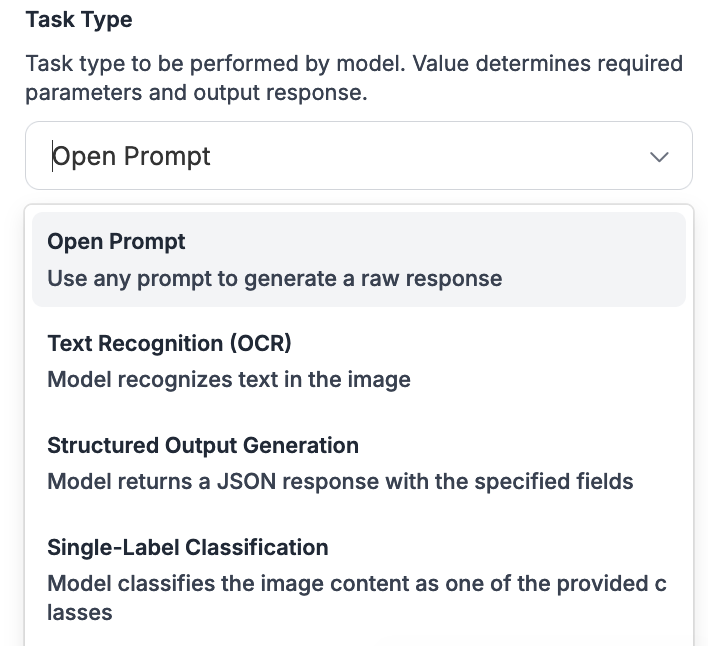 タスクタイプを選択すると、ブロックの出力が自動的に Workflow の出力に追加されます。
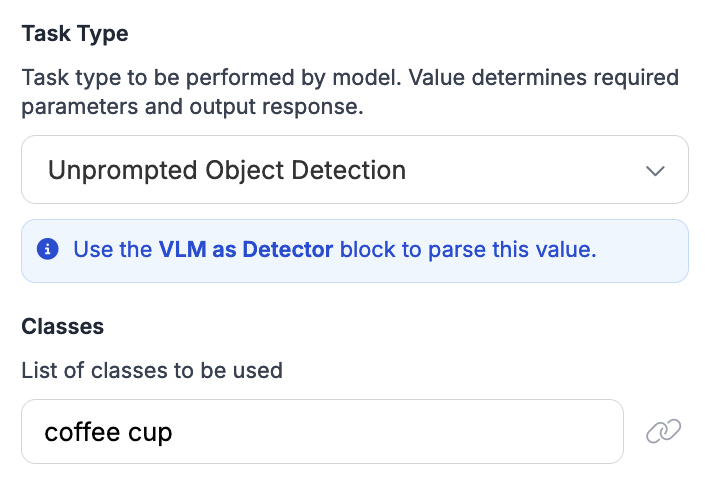
物体検出の設定例は次のとおりです:
タスクタイプを選択すると、ブロックの出力が自動的に Workflow の出力に追加されます。
物体検出の設定例は次のとおりです:
 ### コネクタを追加する
マルチモーダルモデルの出力を他のブロックで使用したい場合は、コネクタを追加する必要があります。
コネクタを使用して、次を処理できます:
* 分類、および;
* バウンディングボックス。
たとえば、Claude 3 がサポートするゼロショット物体検出からバウンディングボックスの値を取得するために、コネクタを追加できます。
このコネクタは、ボックスを、Bounding Box Visualization や Label Visualization などの Visualization ブロックで使用できるように処理します。
### コネクタを追加する
マルチモーダルモデルの出力を他のブロックで使用したい場合は、コネクタを追加する必要があります。
コネクタを使用して、次を処理できます:
* 分類、および;
* バウンディングボックス。
たとえば、Claude 3 がサポートするゼロショット物体検出からバウンディングボックスの値を取得するために、コネクタを追加できます。
このコネクタは、ボックスを、Bounding Box Visualization や Label Visualization などの Visualization ブロックで使用できるように処理します。
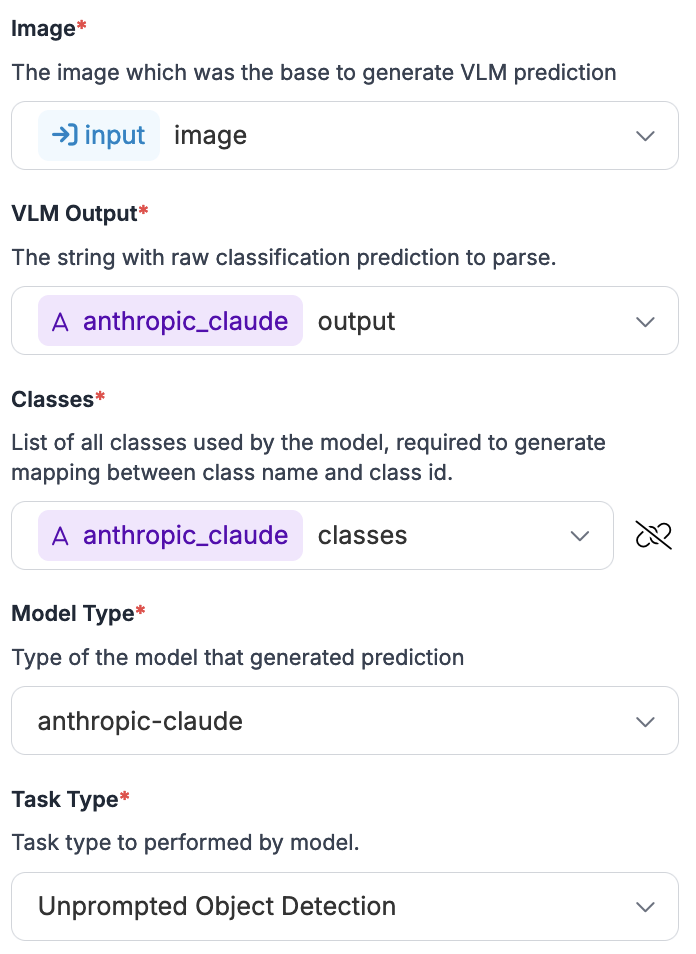
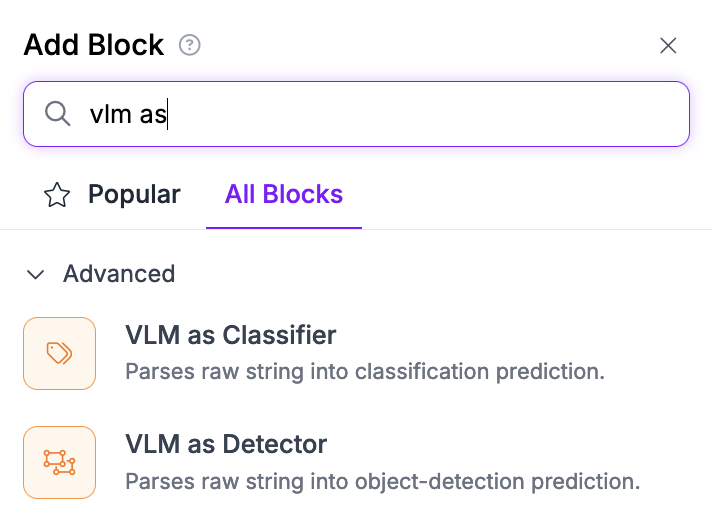 VLM コネクタを選択したら、次を使用するように設定します:
1. 入力画像
2. マルチモーダルブロックの出力
3. マルチモーダルモデルのクラス
4. 使用しているマルチモーダルモデルの名前(この例では、 `anthropic-claude`)
5. マルチモーダルモデルの設定時に選択したタスクタイプ
次に、 *VLM as Detector* ブロックの設定例を示します:
VLM コネクタを選択したら、次を使用するように設定します:
1. 入力画像
2. マルチモーダルブロックの出力
3. マルチモーダルモデルのクラス
4. 使用しているマルチモーダルモデルの名前(この例では、 `anthropic-claude`)
5. マルチモーダルモデルの設定時に選択したタスクタイプ
次に、 *VLM as Detector* ブロックの設定例を示します:
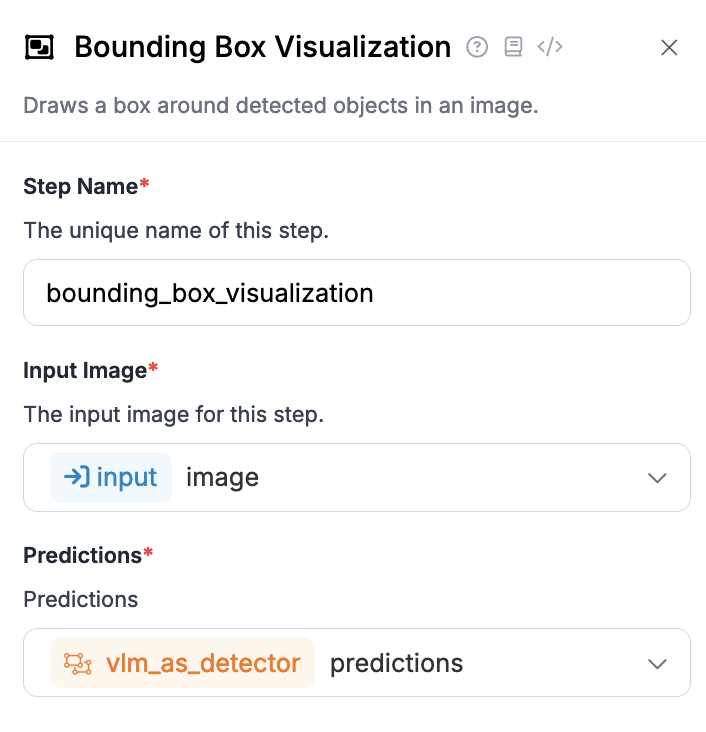
 その後、コネクタの出力を他のブロックで使用できます。
たとえば、コネクタの出力を使用して、Bounding Box Visualization ブロックでバウンディングボックスを表示できます。Bounding Box Visualization ブロックは、入力画像と VLM as Detector ブロックの結果を使用するように設定する必要があります:
その後、コネクタの出力を他のブロックで使用できます。
たとえば、コネクタの出力を使用して、Bounding Box Visualization ブロックでバウンディングボックスを表示できます。Bounding Box Visualization ブロックは、入力画像と VLM as Detector ブロックの結果を使用するように設定する必要があります:
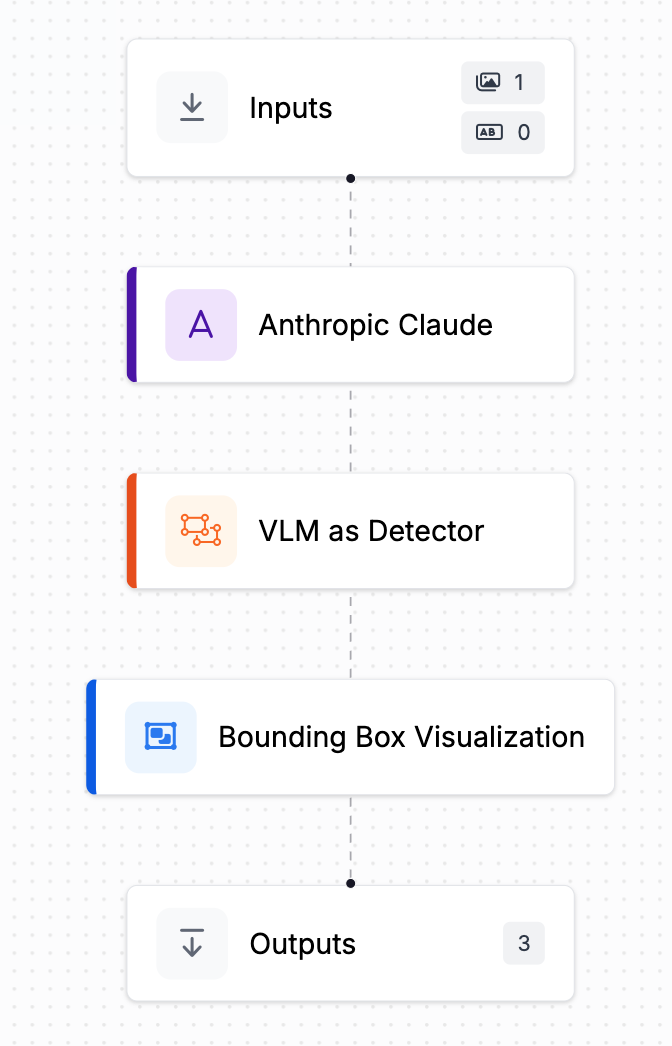
 次は[例のワークフロー](https://app.roboflow.com/workflows/embed/eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ3b3JrZmxvd0lkIjoiUE9YWklzY3VHNzNyMloxQ2JvM3AiLCJ3b3Jrc3BhY2VJZCI6ImtyT1RBYm5jRmhvUU1DZExPbGU0IiwidXNlcklkIjoiSW1GTElaU2tHYk55OXpiNFV1cWxNelBScHBRMiIsImlhdCI6MTczODE5ODA5Nn0.lZjVkJ5GNalFv60YDeHRkONZl5ml_Py2XZgpWcijVtU) マルチモーダルモデルを物体検出に使用するものです:
次は[例のワークフロー](https://app.roboflow.com/workflows/embed/eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ3b3JrZmxvd0lkIjoiUE9YWklzY3VHNzNyMloxQ2JvM3AiLCJ3b3Jrc3BhY2VJZCI6ImtyT1RBYm5jRmhvUU1DZExPbGU0IiwidXNlcklkIjoiSW1GTElaU2tHYk55OXpiNFV1cWxNelBScHBRMiIsImlhdCI6MTczODE5ODA5Nn0.lZjVkJ5GNalFv60YDeHRkONZl5ml_Py2XZgpWcijVtU) マルチモーダルモデルを物体検出に使用するものです: