# 멀티모달 모델 Workflow
Roboflow Workflows는 Workflows에서 multimodal 모델 사용을 지원합니다.
여러 가지 작업에 사용할 수 있는 범용 multimodal 모델은 네 가지가 있습니다. 다음과 같습니다:
* GPT-4o
* Claude
* Gemini
* Florence-2
이 모델들은 다음과 같은 작업에 사용할 수 있습니다:
* 단일 레이블 및 다중 레이블 이미지 분류
* Zero-shot 객체 탐지
* 이미지 캡셔닝 생성
* 그 외 더 많은 작업
Workflows에서 multimodal 모델을 사용하려면 다음이 필요합니다:
1. 모델을 추가합니다.
2. 작업 유형을 선택합니다.
3. 모델의 결과를 다른 Workflows 블록이 이해할 수 있는 형식으로 변환하는 내장 connector를 사용합니다.
각 단계를 하나씩 살펴보겠습니다.
### Multimodal Model 추가
Workflows에서 Claude, Gemini 또는 GPT-4o를 사용하려면, 사용하려는 모델에 해당하는 블록을 추가해야 합니다.
이 가이드에서는 Claude를 사용하는 예시를 살펴보겠습니다.
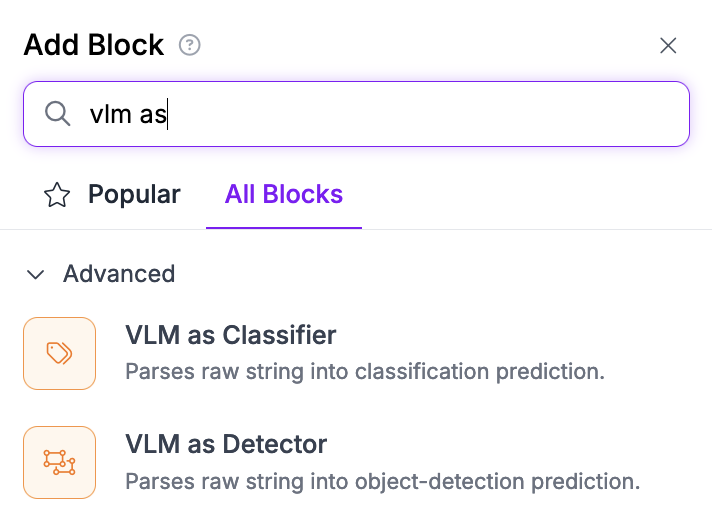
“Add Block”을 클릭하여 블록을 추가합니다. 그런 다음 Claude를 검색합니다:
\\
Claude 블록을 구성할 수 있는 configuration panel이 나타납니다.
{% hint style="info" %}
외부 API를 호출하는 multimodal 모델(GPT-4o 등)을 사용하는 경우, 모델 API key를 설정해야 합니다.
{% endhint %}
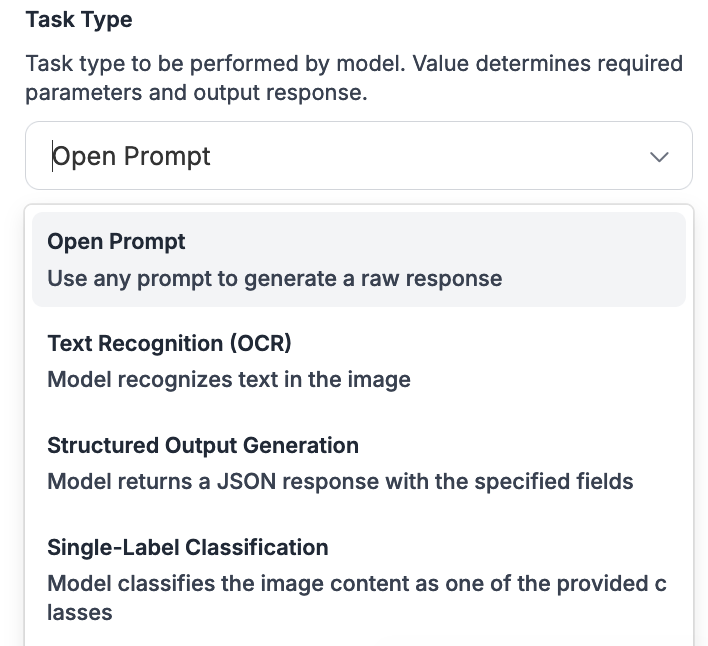
Claude(Gemini 및 GPT-4o 포함)는 다음을 포함한 여러 작업에 사용할 수 있습니다:
* Open prompt: 프롬프트를 multimodal 모델에 직접 전달합니다.
* 텍스트 인식(OCR): 이미지의 문자를 읽습니다.
* 구조화된 출력 생성: 지정된 형식으로 데이터를 반환합니다.
* 단일 레이블 및 다중 레이블 분류: 이미지의 내용을 나타내는 하나 이상의 레이블을 반환합니다.
* Visual question answering: 이미지 내용에 대한 특정 질문에 답합니다.
* Captioning: 이미지 캡션을 반환합니다.
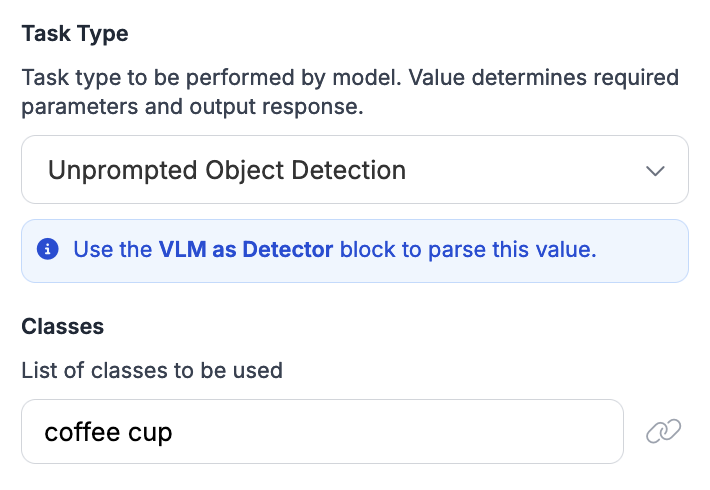
* Unprompted object detection: 이미지 내 객체의 위치에 해당하는 bounding box를 반환합니다.
Task Type 드롭다운에서 이러한 작업을 선택할 수 있습니다:
작업 유형을 선택하면 블록의 출력이 자동으로 Workflow outputs에 추가됩니다.
객체 탐지를 위한 구성 예시는 다음과 같습니다:
### Connector 추가
다른 블록에서 multimodal 모델의 출력을 사용하려면 connector를 추가해야 합니다.
connector를 사용하여 다음을 처리할 수 있습니다:
* 분류, 그리고;
* Bounding box.
예를 들어, Claude 3가 지원하는 zero-shot object detection에서 bounding box 값을 가져오기 위해 connector를 추가할 수 있습니다.
이 connector는 박스를 Bounding Box Visualization 및 Label Visualization과 같은 Visualization 블록에서 사용할 수 있도록 처리합니다.
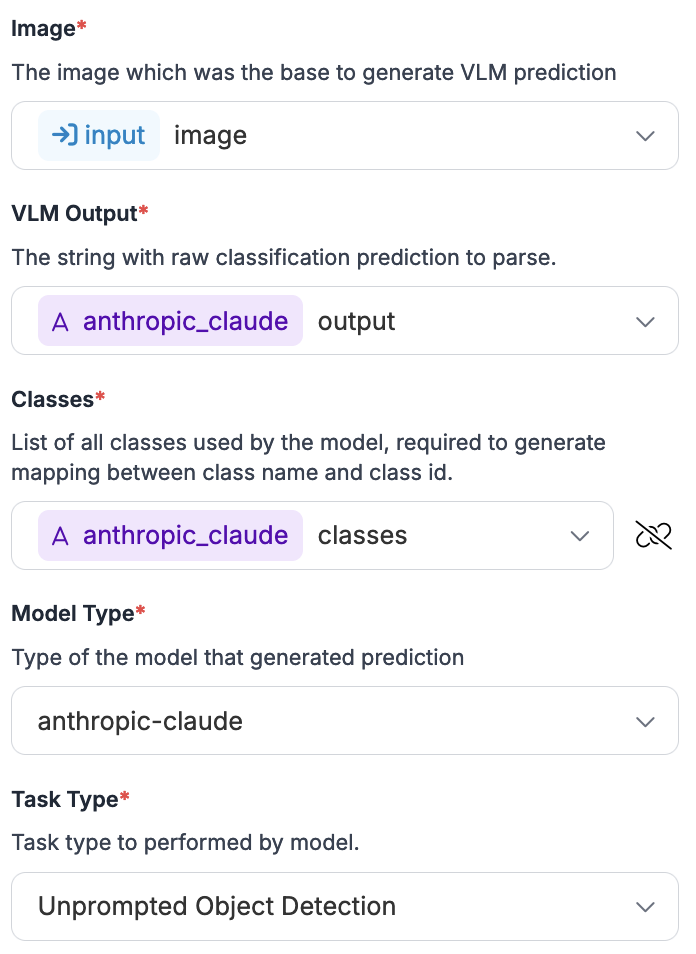
VLM connector를 선택하면 다음을 사용하도록 구성합니다:
1. 입력 이미지
2. multimodal 블록의 출력
3. multimodal 모델의 클래스
4. 사용 중인 multimodal 모델의 이름(이 예시에서는 `anthropic-claude`)
5. multimodal 모델을 설정할 때 선택한 작업 유형
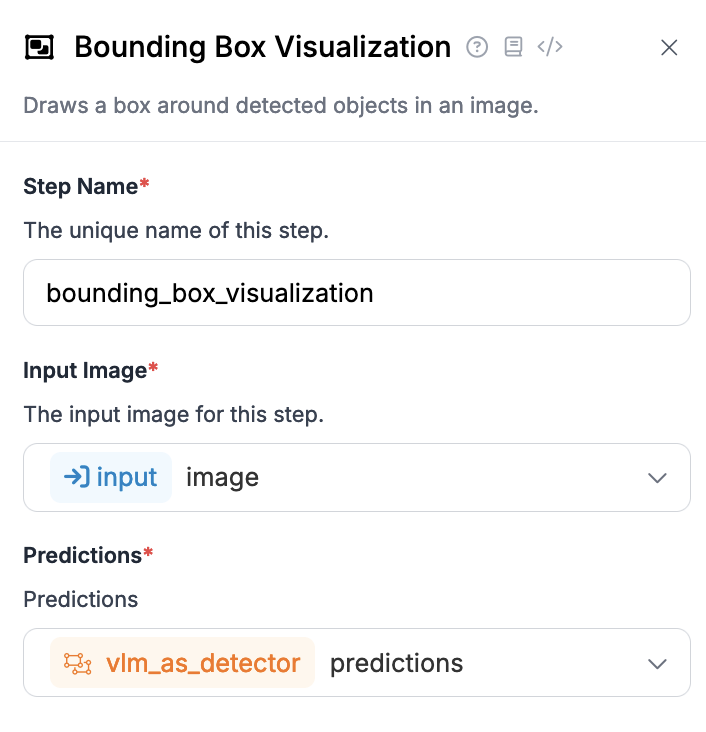
다음은 *VLM as Detector* 블록의 구성 예시입니다:
그런 다음 connector 출력을 다른 블록과 함께 사용할 수 있습니다.
예를 들어, Bounding Box Visualization 블록을 사용하여 connector 출력을 통해 bounding box를 표시할 수 있습니다. Bounding Box Visualization 블록은 입력 이미지와 VLM as Detector 블록의 결과로 구성해야 합니다:
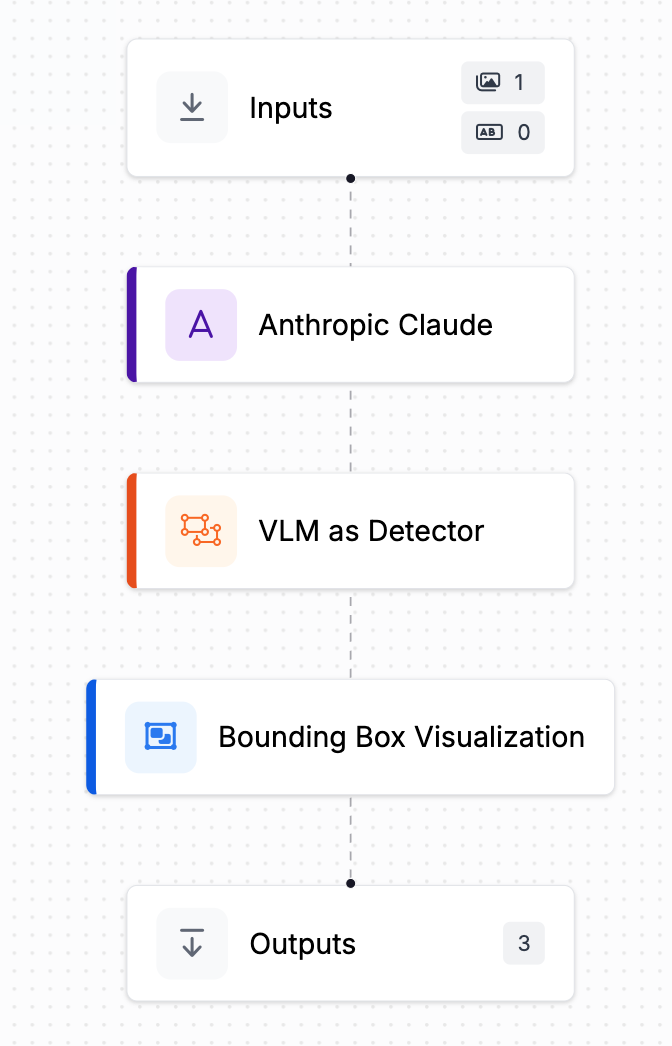
다음은[예시 workflow](https://app.roboflow.com/workflows/embed/eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ3b3JrZmxvd0lkIjoiUE9YWklzY3VHNzNyMloxQ2JvM3AiLCJ3b3Jrc3BhY2VJZCI6ImtyT1RBYm5jRmhvUU1DZExPbGU0IiwidXNlcklkIjoiSW1GTElaU2tHYk55OXpiNFV1cWxNelBScHBRMiIsImlhdCI6MTczODE5ODA5Nn0.lZjVkJ5GNalFv60YDeHRkONZl5ml_Py2XZgpWcijVtU) 를 사용하여 객체 탐지를 수행하는 multimodal 모델의 예시입니다: