> For the complete documentation index, see [llms.txt](https://docs.roboflow.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.roboflow.com/roboflow/roboflow-ko/deploy/batch-processing/troubleshooting.md).
# 문제 해결
이 페이지에는 Batch Processing의 알려진 이슈, 제한 사항, 그리고 우회 방법이 나열되어 있습니다. 여기에 없는 문제가 발생하면, 다음을 통해 신고해 주세요. [지원 채널](https://github.com/roboflow/inference/issues).
## 알려진 제한 사항
* 환경 변수와 로컬 스토리지에 대한 접근이 필요한 일부 Workflow 블록(File Sink 및 Environment Secret Store 등)은 차단되며 실행되지 않습니다.
* 이 서비스는 다음을 정의하는 Workflows에서만 작동합니다. **단일** 입력 이미지 매개변수.
## 기술 세부 정보
* 데이터는 Data Staging에 다음과 함께 저장됩니다. **7일 만료**.
* 각 배치 처리 작업은 여러 단계로 구성됩니다(일반적으로 `processing` 및 `export`). 각 단계는 출력 배치를 생성합니다. 다음을 사용하는 것을 권장합니다. `export` 단계 출력은 효율적인 전송을 위해 압축되기 때문입니다.
* 실행 중인 작업은 `processing` 단계에서 UI와 CLI 모두를 사용해 중단할 수 있습니다.
* 중단되었거나 실패한 작업은 다시 시작할 수 있습니다.
* 이 서비스는 데이터를 자동으로 샤딩하고 병렬로 처리합니다:
* 데이터 양에 따라 머신 수가 자동으로 확장됩니다(일부 작업 부하에서는 처리량이 500k–1M images/hour에 이를 수 있습니다).
* 각 머신은 데이터 청크를 처리하는 여러 worker를 실행합니다. 이는 구성 가능하며, 속도와 비용의 균형을 맞추도록 조정해야 합니다.
* 이미지 작업의 경우, 단일 shard에서 실패한 이미지가 너무 많으면 해당 shard는 중단되고 나머지 작업은 계속 진행됩니다. 이 임계값은 작업별로 설정할 수 있습니다(아래의 [Per-Shard Image Failure Tolerance](#per-shard-image-failure-tolerance) 참조).
## 작업 시간 초과
### 문제
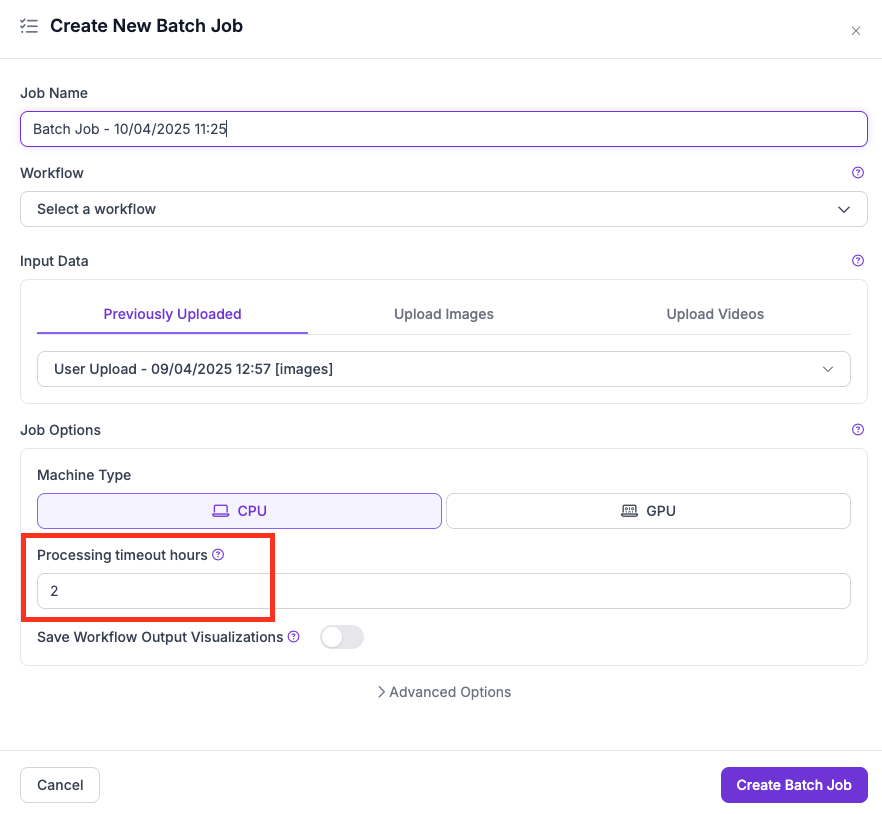
Batch 작업은 다음이 **Processing Timeout Hours** 작업의 크기나 복잡도에 비해 너무 낮게 설정되면 조기에 종료됩니다.
UI의 Processing Timeout 설정
### 세부 정보
타임아웃 설정(UI) 또는 `--max-runtime-seconds` (CLI)는 다음을 정의합니다. **모든 parallel worker에 걸친 최대 누적 머신 실행 시간**.
* **총 계산 시간:** 한도가 2시간이고 작업이 2대의 머신을 생성하면, 각 머신은 최대 1시간 동안 실행될 수 있습니다(2대 x 1시간 = 총 2시간).
* **청크별 분할:** 작업은 병렬 처리를 위해 processing chunk로 분할됩니다. 타임아웃은 chunk에 나뉘어 적용되므로, 청크 수가 많고 타임아웃이 짧으면 청크당 시간이 너무 부족할 수 있습니다.
* **머신 유형이 중요합니다:** 복잡한 Workflows를 CPU에서 실행하면 처리 시간이 크게 증가합니다. 필요한 경우 GPU를 사용하세요.
### 권장 사항
* 대용량 데이터셋 또는 다단계 Workflows의 경우 넉넉한 타임아웃(예: 4\~6시간)으로 시작하세요.
* 향후 타임아웃 설정에 반영할 수 있도록 실제 작업 실행 시간을 모니터링하세요.
* 더 빠른 처리를 위해 chunk 수를 줄이거나 video frame 서브샘플링을 사용하는 것을 고려하세요.
## SAHI가 포함된 Workflow가 너무 오래 실행됨
### 문제
SAHI를 사용하는 작업은 특히 고해상도 입력과 instance segmentation이 결합된 경우 예상보다 훨씬 오래 걸릴 수 있습니다.
### 원인 및 권장 사항
**slice 수가 너무 많음:** SAHI는 탐지를 위해 이미지를 더 작은 slice로 분할합니다. 기본 설정과 고해상도 입력에서는 이미지당 수십 또는 수백 번의 inference가 발생할 수 있습니다.
* Image Slicer 블록 구성을 확인하세요. Workflow 앞부분의 Resize Image 블록을 사용해 slice 수를 줄이거나 입력을 축소하세요.
**SAHI 대신 더 큰 model input size 사용 고려:** 더 큰 입력 차원으로 모델을 학습하면 SAHI가 전혀 필요하지 않을 수 있습니다. 먼저 작은 샘플로 테스트하세요.
**instance segmentation 병목 현상:** SAHI를 instance segmentation과 함께 사용하면 Detections Stitch 블록(특히 NMS 포함)이 큰 병목이 될 수 있습니다. 단일 프레임을 stitch하는 데 수십 초가 걸릴 수 있습니다.
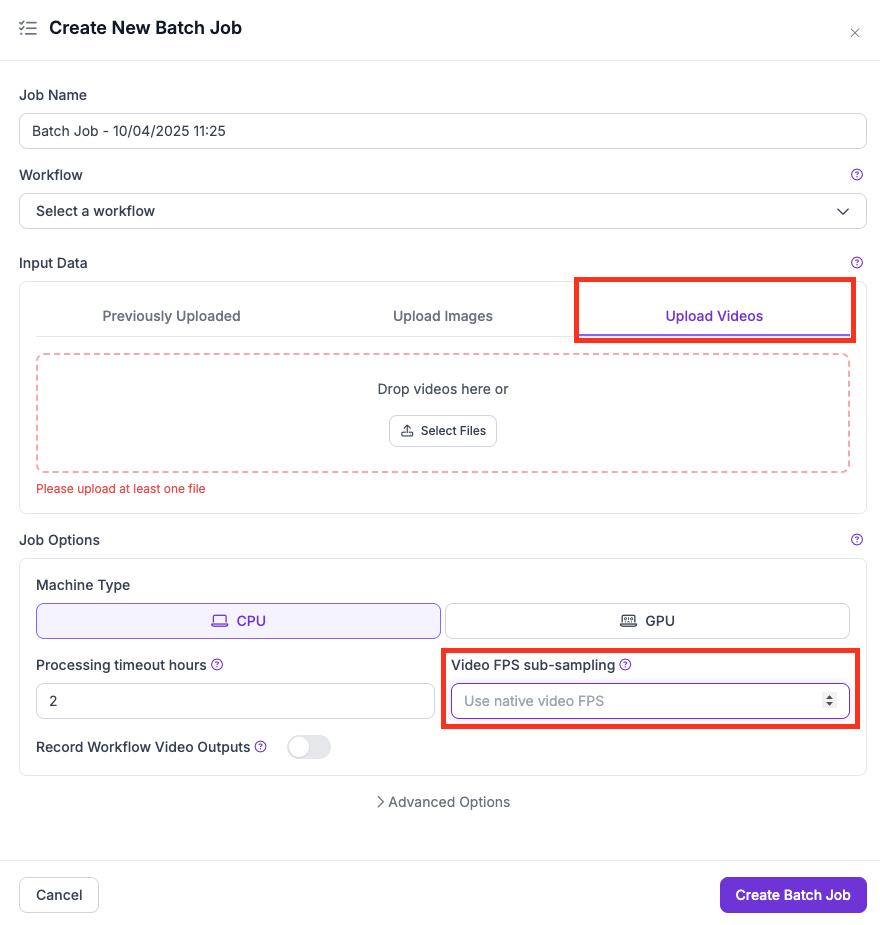
**SAHI를 사용하는 video 작업:** FPS 서브샘플링을 사용해 프레임을 건너뛰세요:
* UI에서 다음을 사용하세요. **Video FPS sub-sampling** 드롭다운에 값을 지정하세요.
* CLI에서는 다음을 사용하세요. `--max-video-fps` 플래그.
UI의 FPS 서브샘플링 설정
## 메모리 부족(OOM) 오류
### 문제
Workflow가 사용 가능한 RAM 또는 VRAM보다 더 많은 메모리를 사용하면 OOM 오류로 작업이 실패합니다.
### 일반적인 원인
* **SAHI + Instance Segmentation:** 이 조합은 메모리를 매우 많이 사용합니다. SAHI는 inference 호출 수를 늘리고, instance segmentation은 큰 출력(mask, score 등)을 생성하므로, 자주 충돌로 이어집니다.
* **머신당 worker 수가 너무 많음:** 여러 worker는 경량 Workflow의 비용과 속도를 최적화하지만, 무거운 Workflow(여러 대형 모델, 복잡한 후처리)는 사용 가능한 메모리를 초과하게 됩니다.
### 권장 사항
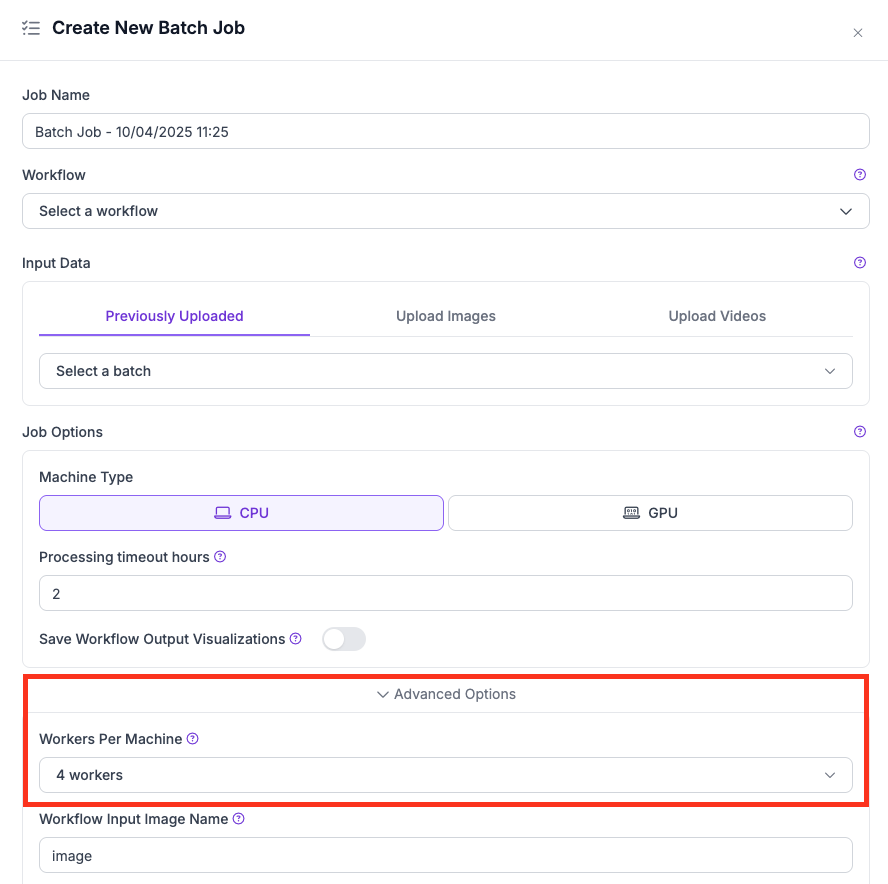
* 대형 모델, SAHI 또는 고해상도 입력이 있는 Workflows에서는 머신당 worker 수를 더 적게(예: 1 또는 2) 사용하세요.
* 다음을 낮추세요. **Workers Per Machine** Advanced Options에서 해당 값을.
* 모델에 더 높은 메모리 처리량이 필요하다면 CPU에서 GPU로 전환하세요.
* 대규모 배치를 실행하기 전에 작은 데이터셋으로 Workflow를 테스트하세요.
* 입력 해상도를 낮추거나 불필요한 블록을 제거해 Workflow를 단순화하세요.
UI의 머신당 worker 설정
## Per-Shard Image Failure Tolerance
### 작동 방식
이미지 배치 작업은 병렬로 실행되는 shard로 분할됩니다. 각 shard는 처리 중에 실패한 이미지 수를 추적합니다. 단일 shard 내 실패율이 임계값을 초과하면 해당 shard는 중단됩니다. 작업의 나머지 부분은 영향 없이 계속 진행됩니다.
기본적으로 플랫폼은 고정된 실패 임계값을 적용합니다. 작업 생성 요청 본문에서 다음을 설정하여 작업별로 이를 덮어쓸 수 있습니다. `maxImageFailureRate` 작업 생성 요청 본문에. 값은 다음 사이의 실수여야 합니다. `0.0` 및 `1.0`:
* `0.0` 0은 허용 오차가 없음을 의미합니다(첫 실패 시 shard 중단).
* `1.0` 이미지가 몇 개 실패하든 shard가 절대 중단되지 않음을 의미합니다.
* 필드를 생략하거나 다음으로 설정하여 `null` 플랫폼 기본값을 사용하세요.
이 매개변수는 이미지 작업에만 적용됩니다. video 작업에서는 지원되지 않습니다.
### API를 통한 설정
다음을 포함하세요. `maxImageFailureRate` 작업 생성 payload에:
```json
{
"type": "simple-image-processing-v1",
"maxImageFailureRate": 0.1,
...
}
```
이 값은 실패했거나 중단된 작업을 다시 시작할 때, restart parameters override에 포함하여 덮어쓸 수도 있습니다.