# NVIDIA GPU (Legacy)
{% hint style="warning" %}
यह पृष्ठ का एक पुराना संस्करण है [यहाँ इस पृष्ठ](https://docs.roboflow.com/roboflow/roboflow-hi/deploy/sdks/enterprise-gpu).
{% endhint %}
## स्थापना आवश्यकताएँ
इन तैनाती विकल्पों के लिए एक आवश्यक है [Roboflow Enterprise लाइसेंस](https://roboflow.com/enterprise).
Enterprise GPU inference सर्वर को तैनात करने के लिए, आपको पहले NVIDIA ड्राइवर और [nvidia-container-runtime](https://github.com/NVIDIA/nvidia-container-runtime)इंस्टॉल करने होंगे, जिससे docker आपके GPU को inference सर्वर तक पास-थ्रू कर सके। आप यह जांचने के लिए परीक्षण कर सकते हैं कि आपकी प्रणाली में पहले से `nvidia-container-runtime` है और नीचे दिए गए कमांड से आपकी स्थापना सफल रही या नहीं:
```
docker run --gpus all -it ubuntu nvidia-smi
```
यदि आपकी स्थापना सफल रही है, तो आपको कंटेनर के भीतर से आपका GPU डिवाइस दिखाई देगा:
```
Tue Nov 9 16:04:47 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: N/A |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:1E.0 Off | 0 |
| N/A 41C P0 56W / 149W | 504MiB / 11441MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
```
GPU TRT कंटेनर बनाने से पहले आपको अपने प्रोजेक्ट की जानकारी चाहिए। इसमें आपका Roboflow API Key, Model ID और Model Version शामिल हैं। यदि आपके पास यह जानकारी नहीं है तो आप इस लिंक का अनुसरण कर सकते हैं [अपने प्रोजेक्ट की जानकारी खोजें](https://github.com/roboflow-ai/roboflow-docs/blob/main/deploy/legacy-documentation/broken-reference/README.md)। एक बार मिलने पर, इन तीन चर(variables)को बाद के उपयोग के लिए सुरक्षित कर लें।
## Enterprise GPU TRT
Enterprise GPU TRT तैनाती आपके मॉडल को डिवाइस पर संकलित करती है, आपके उपलब्ध हार्डवेयर के लिए अनुकूलन करती है। वर्तमान में GPU TRT कंटेनर के लिए तीन तैनाती विकल्प हैं। AWS के माध्यम से EC2 इंस्टेंस पर तैनात करना, Windows के माध्यम से WSL2 पर तैनात करना, और Windows पर Anaconda के माध्यम से तैनात करना।
### Amazon EC2 तैनातियाँ
#### AMI चुनें और EC2 इंस्टेंस लॉन्च करें
TRT GPU कंटेनर को EC2 इंस्टेंस पर चलाने के लिए, पहले आपको उपयुक्त AMI चुनना होगा। AMI को आप अपनी इंस्टेंस लॉन्च करते समय कॉन्फ़िगर कर सकते हैं और इंस्टेंस लॉन्च करने से पहले इसे चुनना चाहिए। हम उपयोग करने जा रहे हैं **NVIDIA GPU-Optimized AMI** जो Ubuntu 20.04, Docker और अन्य आवश्यकताएँ पहले से इंस्टॉल के साथ आता है।
NVIDIA GPU-Optimized AMI के साथ EC2 इंस्टेंस कॉन्फ़िगर करें
#### SSH के माध्यम से EC2 इंस्टेंस में लॉगिन करें
आपके EC2 इंस्टेंस के सफलतापूर्वक चलने के बाद, हम SSH और अपने Amazon Keypair का उपयोग करके उसमें लॉग इन कर सकते हैं। Amazon उनके इंस्टेंस से कनेक्ट करने के लिए दस्तावेज़ प्रदान करता है [यहाँ](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AccessingInstancesLinux.html)। यदि आपका Keypair तैयार है और आप अपने EC2 इंस्टेंस का Public DNS जानते हैं, तो नीचे दिए गए कमांड का उपयोग करके हम इंस्टेंस में लॉग इन कर सकते हैं। इस इंस्टेंस के लिए डिफ़ॉल्ट `instance-user-name` इस इंस्टेंस के लिए होना चाहिए *ubuntu.*
```
ssh -i /path/key-pair-name.pem instance-user-name@instance-public-dns-name
```
#### TRT GPU Docker कंटेनर शुरू करें
एक बार जब आप SSH के माध्यम से EC2 इंस्टेंस में लॉग इन कर लेते हैं। हम निम्नलिखित कमांड के साथ Docker कंटेनर शुरू कर सकते हैं:
```
sudo docker run --gpus all -p 9001:9001 --network="host" roboflow/inference-server-trt:latest
```
#### इंजन संकलित करें और Inference चलाएँ
सर्वर पर base64 एन्कोड की गई छवि पोस्ट करके अपने मॉडल पर inference चलाएँ - यदि यह पहली बार है जब आपने बिना कैश के अपना मॉडल संकलित किया है, तो इनफेर करने से पहले यह संकलित होगा:
```
base64 your_img.jpg | curl -d @- "http://0.0.0.0:9001/[YOUR MODEL]/[YOUR VERSION]?api_key=[YOUR API KEY]"
```
### Anaconda तैनातियाँ
#### अपना Anaconda वातावरण सेट-अप करें
TRT कंटेनर को चलाने के लिए [Anaconda](https://www.anaconda.com/) या [Miniconda](https://docs.conda.io/en/latest/miniconda.html)के लिए, हमें अपना conda environment बनाना होगा और Docker इंस्टॉल करना होगा। अपने वातावरण बनाने के लिए हम Anaconda टर्मिनल के अंदर नीचे दिए गए कमांड्स का उपयोग कर सकते हैं।
```python
conda create -n TRT python=3.8
conda activate TRT
pip install pybase64
```
#### Anaconda Environment में Docker इंस्टॉल करें
आप Docker को डाउनलोड और चलाने के लिए उपयोग कर सकते हैं [Docker Desktop](https://www.docker.com/products/docker-desktop/) या आप Docker को इंस्टॉल कर सकते हैं `conda-forge`के माध्यम से। नीचे का कोड Anaconda के recipe manager का उपयोग करके Docker इंस्टॉल करेगा।
```
conda install -c conda-forge docker
```
#### Anaconda Environment के अंदर Docker कंटेनर चलाएँ
यदि आपने Docker Desktop इंस्टाल किया है, तो कंटेनर तक पहुँचने के लिए सुनिश्चित करें कि यह चल रहा हो। जिन लोगों ने Docker Desktop डाउनलोड नहीं किया है वे हमारे पिछले `conda-forge` इंस्टॉल प्रक्रिया।
Once your Anaconda environment can successfully access Docker. We can start the Docker container with the following command:
```
docker run --gpus all -p 9001:9001 roboflow/inference-server-trt:latest
```
#### इंजन संकलित करें और Inference चलाएँ
एक और Anaconda टर्मिनल खोलें और उस निर्देशिका पर जाएँ जिसमें वह डेटा है जिस पर आप inference चलाना चाहते हैं। सर्वर पर base64 एन्कोड की गई छवि पोस्ट करके अपने मॉडल पर inference चलाएँ - यदि यह पहली बार है जब आपने बिना कैश के अपना मॉडल संकलित किया है, तो इनफेर करने से पहले यह संकलित होगा:
```
pybase64 encode your_img.jpg | curl -d @- "http://localhost:9001/[YOUR MODEL]/[YOUR VERSION]?api_key=[YOUR API KEY]"
```
### Windows Subsystem तैनातियाँ
#### Microsoft Store से Ubuntu डाउनलोड करें
जो लोग हमारे TRT कंटेनर को Windows पर चलाना चाहते हैं, उनके लिए Anaconda के अलावा एक अन्य विकल्प WSL2 का उपयोग करना है। Windows Subsystem for Linux किसी भी Windows 10+ उपयोगकर्ता को टर्मिनल इंटरफ़ेस के माध्यम से Windows के साथ असिंक्रोनस रूप से Ubuntu चलाने की अनुमति देता है। आप Microsoft Store में मुफ्त में Ubuntu 20.04.5 ढूँढ सकते हैं और डाउनलोड कर सकते हैं। स्थापना के बाद, अपने विंडो खोज बार में Ubuntu टाइप करके और एप्लिकेशन शुरू करके WSL2 चलाएँ।
Microsoft Store से WSL2 स्थापित करें
#### WSL2 पर Docker इंस्टॉल करें (वैकल्पिक)
Ubuntu 20.04.5 LTS में Docker पहले से इंस्टॉल के साथ आना चाहिए, लेकिन यदि यह नहीं है तो Ubuntu में Docker इंस्टॉल करने के लिए नीचे कुछ उपयोगी कमांड दिए गए हैं। Anaconda इंस्टॉलेशन के समान, आप यह भी चला सकते हैं [Docker Desktop](https://www.docker.com/products/docker-desktop/) डॉकर स्थापित करने की आवश्यकता को बायपास करने के लिए। पूर्ण दस्तावेज़ यहाँ पाया जा सकता है: [Ubuntu पर Docker Engine इंस्टॉल करें](https://docs.docker.com/engine/install/ubuntu/)
```
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
```
#### WSL2 के अंदर Docker कंटेनर चलाएँ
एक बार जब आपने अपने WSL2 वातावरण पर Docker सफलतापूर्वक इंस्टॉल कर लिया है, तो हम TRT कंटेनर चलाने के लिए Docker का उपयोग कर सकते हैं। कंटेनर चलाने के लिए, हमें नीचे दिए गए कमांड का उपयोग करने की आवश्यकता है जो पोर्ट 9001 पर इनफरेंस स्वीकार करना शुरू कर देगा।
```
sudo docker run --gpus all -p 9001:9001 roboflow/inference-server-trt:latest
```
#### इंजन संकलित करें और Inference चलाएँ
अब जब GPU TRT कंटेनर Docker में चल रहा है। हम एक और Ubuntu टर्मिनल खोल सकते हैं जिसका उपयोग docker कंटेनर को inference डेटा भेजने के लिए किया जाएगा। उपयोग करें `ls` और `cd` उस स्थान पर जाएँ जहाँ वह छवि है जिसपर आप inference चलाना चाहते हैं और नीचे दिए गए कमांड का उपयोग करें।
यदि यह आपकी पहली inference है, तो आपके मॉडल को संकलित होने में कुछ समय लगेगा। मॉडल के बनने के बाद आगे की inference तेज़ होंगी।
```
base64 your_img.jpg | curl -d @- "http://0.0.0.0:9001/[YOUR MODEL]/[YOUR VERSION]?api_key=[YOUR API KEY]"
```
## विस्तारित कार्यक्षमता
### अपने मॉडल को कैश करना
कुछ मामलों में, आप चाह सकते हैं कि अपना मॉडल लोकली कैश कर लें ताकि सर्वर हर बार शुरू होने पर बाहरी Roboflow सर्वरों से मॉडल डाउनलोड करने की आवश्यकता न पड़े।
अपने मॉडल को ऑफ़लाइन कैश करने के लिए, पहले एक docker volume बनायें:
```
docker volume create roboflow
```
फिर, अपने docker volume को माउंट करके सर्वर शुरू करें `/cache` डायरेक्टरी:
```
sudo docker run --gpus all -p 9001:9001 --network="host" --mount source=roboflow,target=/cache roboflow/inference-server-trt:latest
```
### Docker Compose के साथ Multi-GPU समर्थन
हमने Roboflow TRT Docker कंटेनर का उपयोग करने के उदाहरणों तक त्वरित पहुँच के लिए एक रिपोजिटरी विकसित की है। शुरू करने के लिए, हमारे docker compose टेम्पलेट को डाउनलोड करने के लिए नीचे git clone कमांड चलाएँ।
```python
git clone https://github.com/roboflow/trt-demos.git
```
इस उदाहरण के लिए, हमने docker को 8 GPUs के साथ एक load balancer चलाने के लिए कॉन्फ़िगर किया है। यदि आपको 8 से कम GPUs चलाने की आवश्यकता है। हम उस पर कवर करेंगे [यहाँ](#configuring-docker-compose.yaml-and-roboflow-nginx.conf).
#### लोड बैलेंसर बनाना
लोड बैलेंसर docker कंटेनर बनाने के लिए नीचे दिए गए कमांड का उपयोग करें। यदि आप जिस लोड बैलेंसर का हम उपयोग कर रहे हैं उसके बारे में अधिक जानकारी चाहते हैं तो आप वह जानकारी पा सकते हैं [यहाँ](http://nginx.org/en/docs/).
```
docker build . -t lb
```
#### Docker Compose शुरू करना
सुनिश्चित करें कि docker-compose.yaml फ़ाइल में सेवाओं के नाम .conf/roboflow-nginx.conf फ़ाइल में सही रूप से परिलक्षित हों फिर docker compose चलाएँ।
```
docker-compose up
```
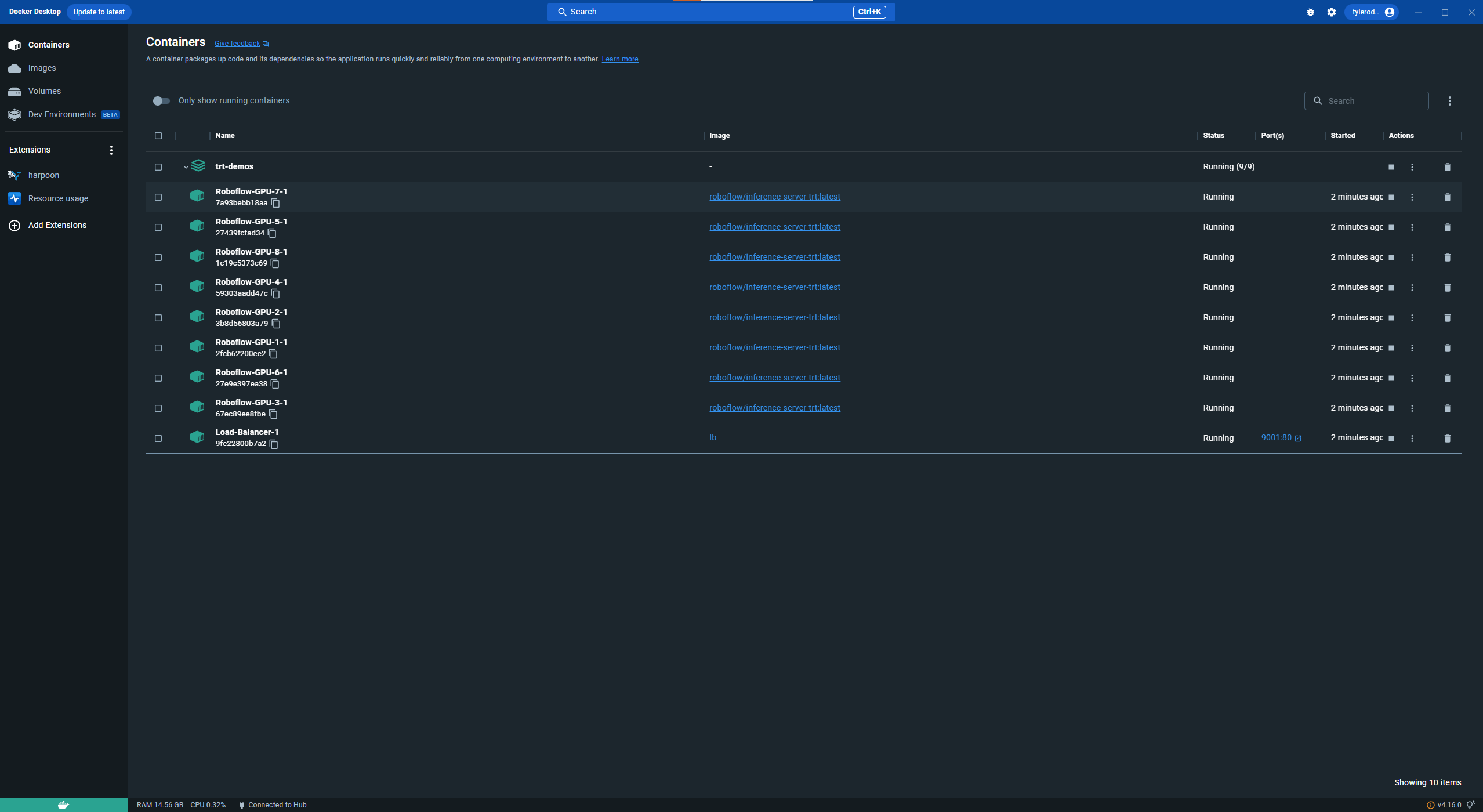
आपका Docker अब कई GPU कंटेनरों को चालू कर रहा होगा जो सभी एक वॉल्यूम और लोड बैलेंसर के साथ पोर्ट साझा करते हैं। इस तरह लोड बैलेंसर प्रत्येक कंटेनर के थ्रूपुट का प्रबंधन कर सकता है ताकि गति अनुकूल रहे। यदि आप Docker Desktop में चल रहे हैं, तो सफल बूट अप कुछ इस तरह दिखाई देनी चाहिए।
#### Inference चलाना
अब जब आपके पास आपके GPU कंटेनर और लोड बैलेंसर चल रहे हैं। आप लोड बैलेंसर के साथ इंटरैक्ट कर सकते हैं जो आपके सभी अनुरोधों को संबंधित GPU तक मार्गित करेगा ताकि अनुकूल थ्रूपुट बना रहे।
आप नीचे दिए गए curl कमांड्स में से एक का उपयोग करके एक नया टर्मिनल खोलकर लोड बैलेंसर का परीक्षण कर सकते हैं।
```
# Amazon EC2 तैनातियाँ
base64 your_img.jpg | curl -d @- "http://0.0.0.0:9001/[YOUR MODEL]/[YOUR VERSION]?api_key=[YOUR API KEY]"
# Anaconda तैनातियाँ
pip install pybase64
pybase64 encode your_img.jpg | curl -d @- "http://localhost:9001/[YOUR MODEL]/[YOUR VERSION]?api_key=[YOUR API KEY]"
# Windows Subsystem Linux
base64 your_img.jpg | curl -d @- "http://0.0.0.0:9001/[YOUR MODEL]/[YOUR VERSION]?api_key=[YOUR API KEY]"
```
#### अपने Docker Compose फ़ाइलों को कॉन्फ़िगर करना
डिफ़ॉल्ट 8 GPUs से कम चलाने के लिए आपको इस रिपो के कुछ फाइलों में कुछ बदलाव करने होंगे। पहली फाइल जिसे हम देखेंगे वह docker-compose.yaml है जिसमें Roboflow-GPU-1, Roboflow-GPU-2 आदि जैसी कई सेवाएँ हैं। ये सेवाएँ वो हैं जो docker कंटेनरों को चलाती हैं और प्रत्येक GPU से जुड़ती हैं।
यदि हम केवल 3 GPUs चलाना चाहते हैं, तो हम Roboflow-GPU-1, Roboflow-GPU-2 और Roboflow-GPU-3 को छोड़कर अन्य सभी सेवाओं को हटा सकते हैं। किसी सेवा को हटाने के लिए उस सेवा के नाम वाली लाइन और उसके नीचे की सभी लाइनों को हटाएँ जब तक कि अगला सेवा नाम न आ जाए।
{% code title="docker-compose.yaml" lineNumbers="true" %}
```yaml
version: "3"
services:
Roboflow-GPU-1:
image: roboflow/inference-server-trt:latest
restart: always
volumes:
- shared-volume:/cache
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]
Roboflow-GPU-2:
image: roboflow/inference-server-trt:latest
restart: always
volumes:
- shared-volume:/cache
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['1']
capabilities: [gpu]
```
{% endcode %}
अगली फ़ाइल जिसे हमें संपादित करने की आवश्यकता है वह conf फ़ोल्डर के अंदर मिली roboflow-nginx.conf होगी।
8 से 3 GPUs पर जाने के हमारे उदाहरण को जारी रखते हुए। हमें upstream myapp1 में कुछ server लाइनों को हटाने की आवश्यकता होगी। विशेष रूप से लाइन 17 से 21 अब आवश्यक नहीं हैं क्योंकि वे हमारे लक्ष्य संख्या से अधिक हो जाएंगे।
{% code title="roboflow-nginx.conf" lineNumbers="true" %}
```properties
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
upstream myapp1 {
server Roboflow-GPU-1:9001;
server Roboflow-GPU-2:9001;
server Roboflow-GPU-3:9001;
server Roboflow-GPU-4:9001;
server Roboflow-GPU-5:9001;
server Roboflow-GPU-6:9001;
server Roboflow-GPU-7:9001;
server Roboflow-GPU-8:9001;
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
}
```
{% endcode %}
इन दो फ़ाइलों को बदलने के बाद, आप docker-compose ट्यूटोरियल के साथ जारी रखने में सक्षम होना चाहिए [लोड बैलेंसर का निर्माण](#building-the-load-balancer).
### TRT कंटेनर के साथ Multi-Stream का उपयोग करना
कुछ मामलों में, आपके पास कई कैमरा स्ट्रीम हो सकती हैं जिन्हें आप समान TRT कंटेनर पर समान GPU पर समानांतर रूप से प्रोसेस करना चाहते हैं। अपने TRT कंटेनर में कई मॉडल सेवाएँ स्पिन अप करने के लिए निर्दिष्ट करें `--env NUM_WORKERS=[desired num_workers]`\
\
NVIDIA V100 पर, हमने पाया कि 2-4 workers ने इष्टतम लेटेंसी प्रदान की।
NVIDIA V100 पर Roboflow Accurate मॉडल पर TRT मल्टी-स्ट्रीम के लिए बेंचमार्क सांख्यिकी
### TRT कंटेनर में GPU डिवाइस ID को एक्सपोज़ करना
कुछ मामलों में, आप चाहते हैं कि आपका TRT कंटेनर किसी विशिष्ट GPU या vGPU पर चले। आप ऐसा कर सकते हैं निर्दिष्ट करके `CUDA_VISIBLE_DEVICES=[DESIRED GPU OR MIG ID]`\\
## समस्याओं का निवारण
पहले, जांचें कि आपके अनुरोध में उचित मॉडल संस्करण अनुरोध पैरामीटर मौजूद हैं:
#### [अपने प्रोजेक्ट की जानकारी का पता लगाना](https://app.gitbook.com/s/e5GEiPeDoFksvZv1vH3A/authentication/workspace-and-project-ids)
जांचें कि नवीनतम कंटेनर खींचा गया है:\\
`sudo docker pull roboflow/inference-server-trt:latest`\
\
यदि cache volume का उपयोग कर रहे हैं, तो उसे साफ़ करें:
`sudo docker volume rm roboflow`
`sudo docker volume create roboflow`
NVIDIA docker GPU ड्राइवरों की पुनः-जाँच करें:
`docker run --gpus all -it ubuntu nvidia-smi`
रिलॉन्च!\
\
यदि तैनाती त्रुटियाँ बनी रहती हैं, तो सर्वर लॉग्स की कॉपी अपने Roboflow प्रतिनिधि को भेजें और हम सहायता के लिए कूदेंगे।

.png?alt=media)